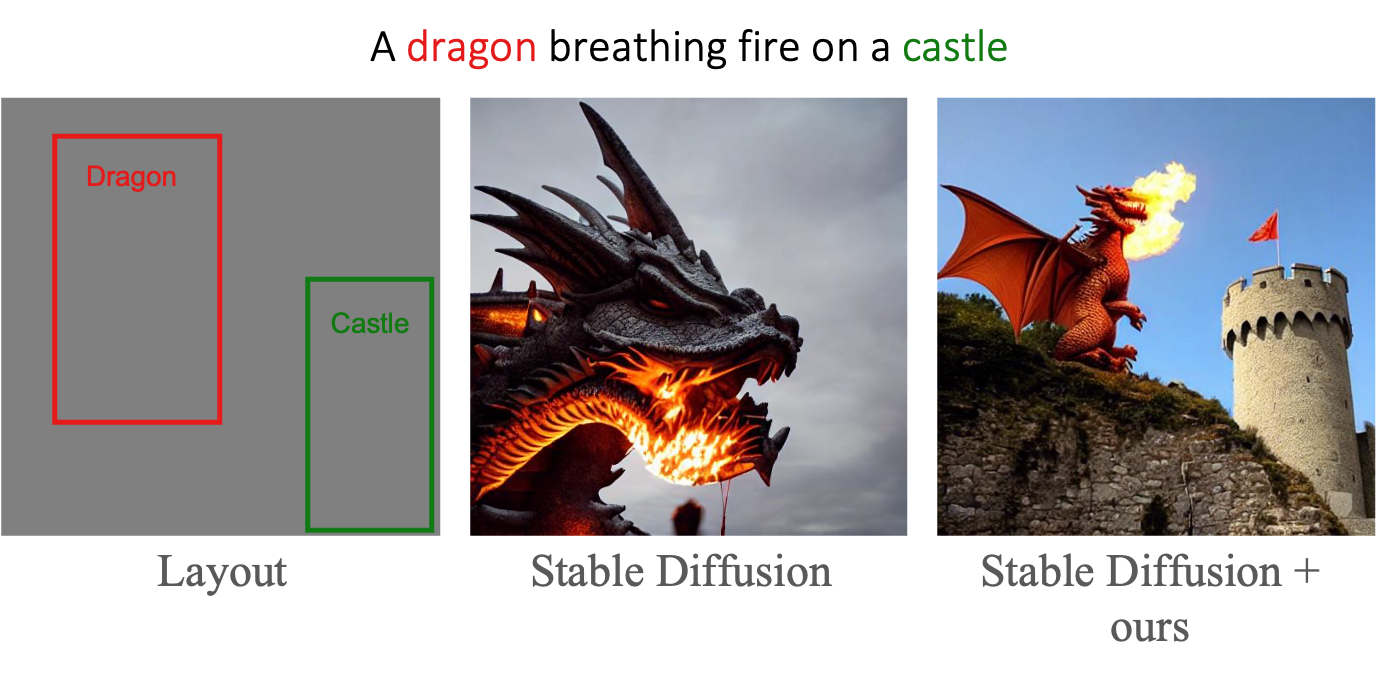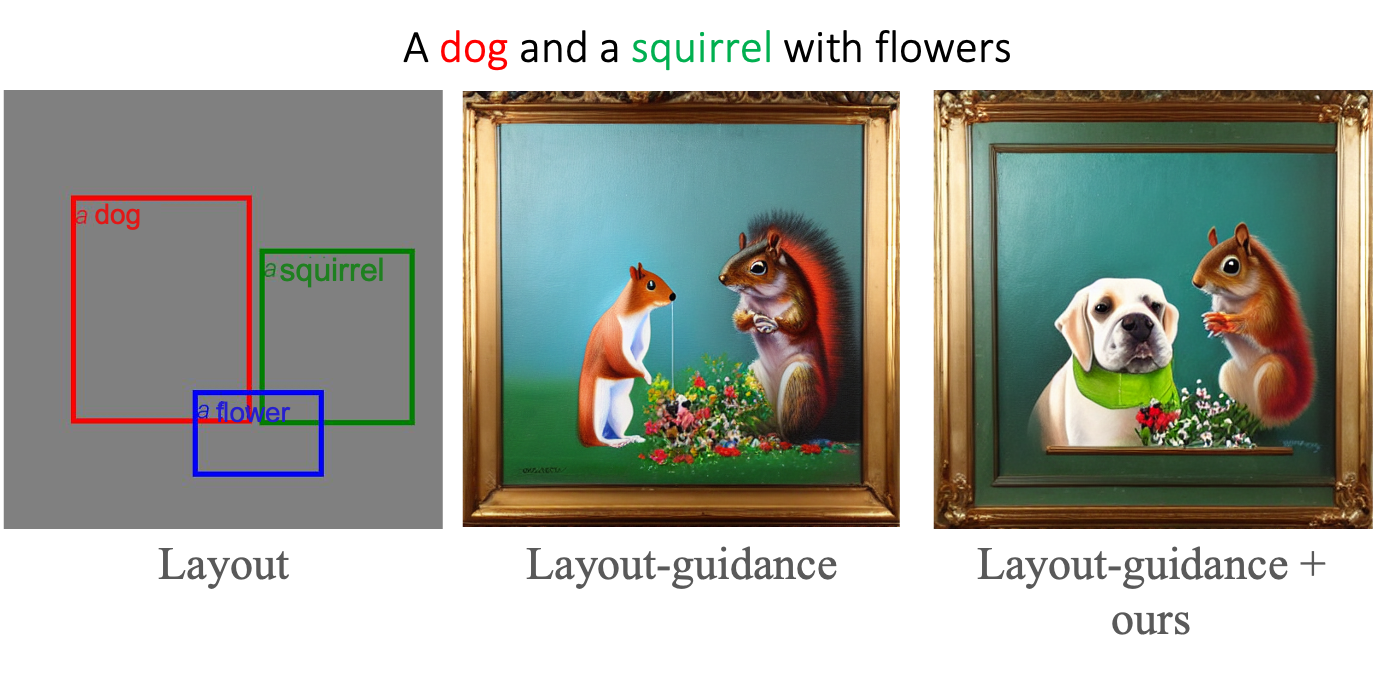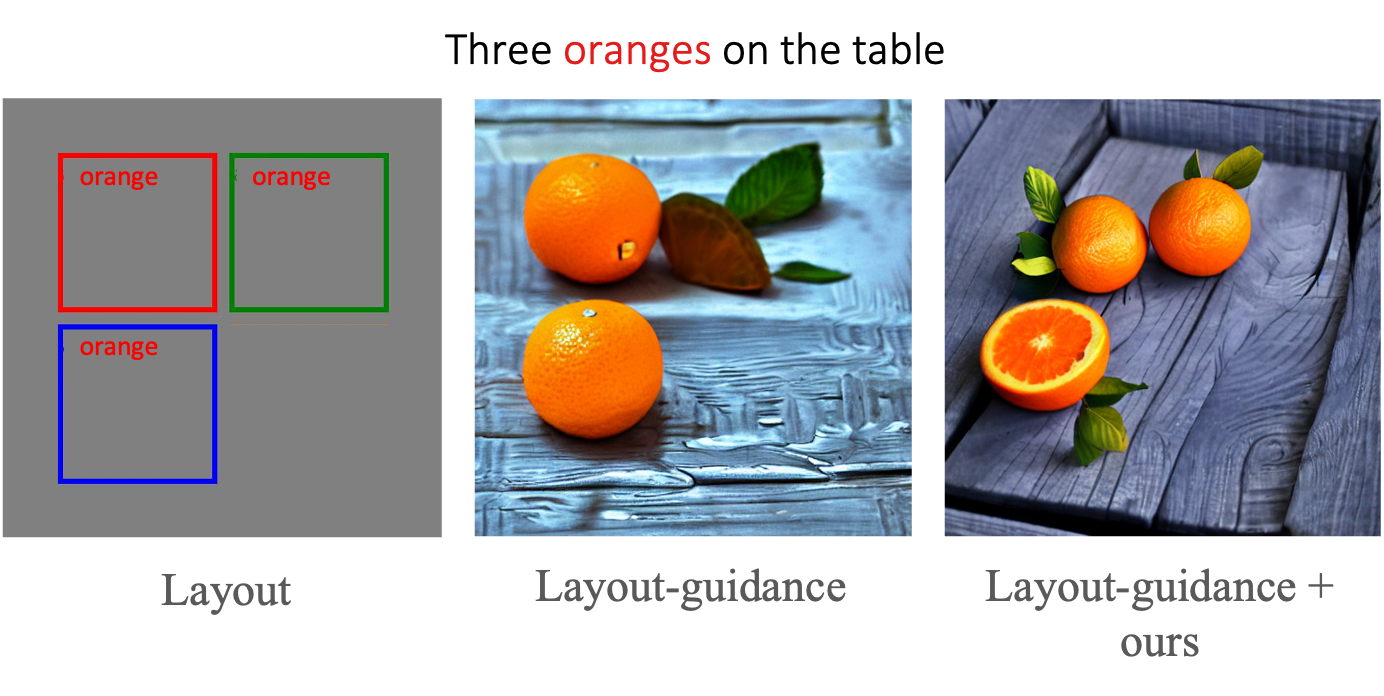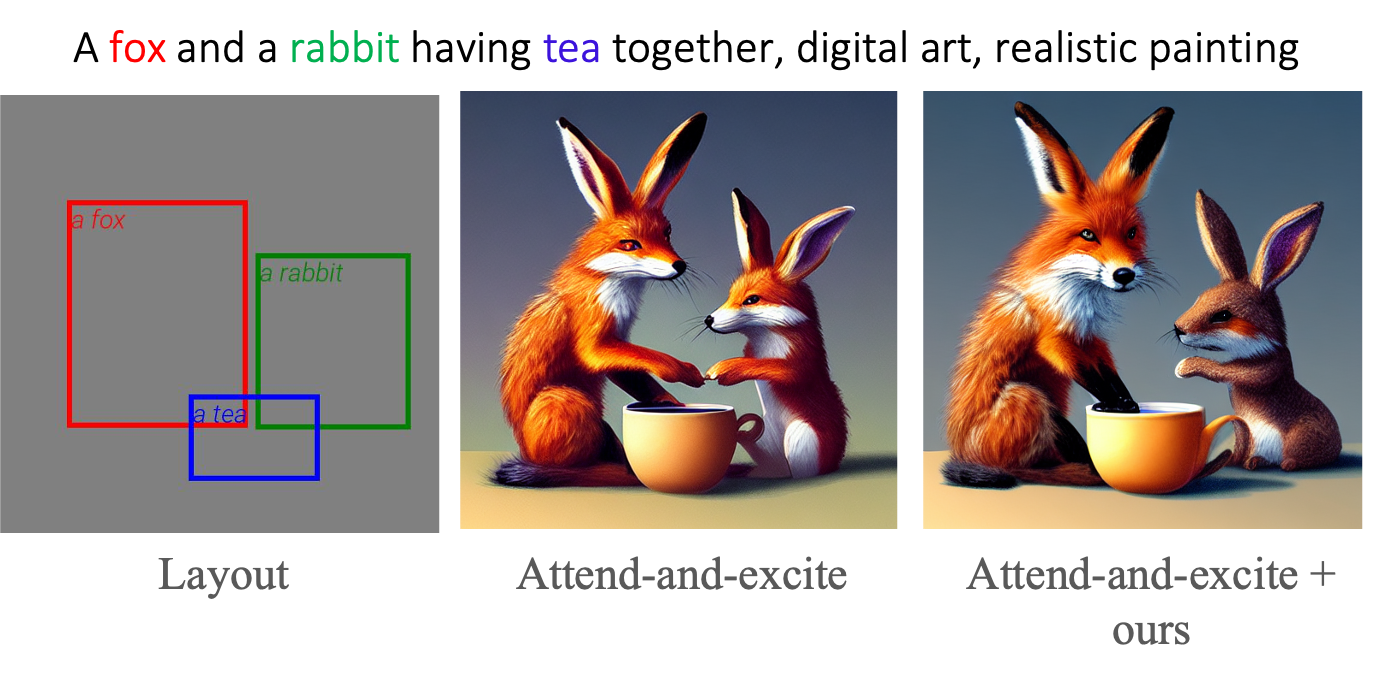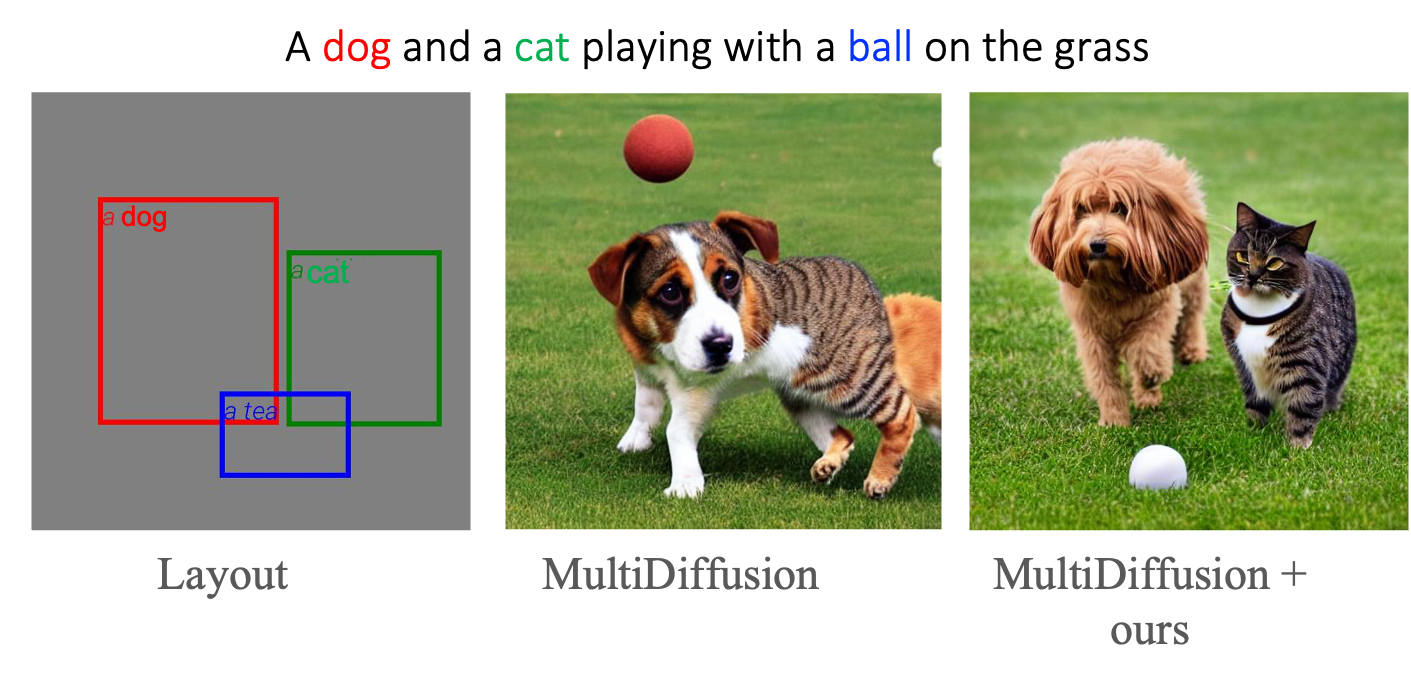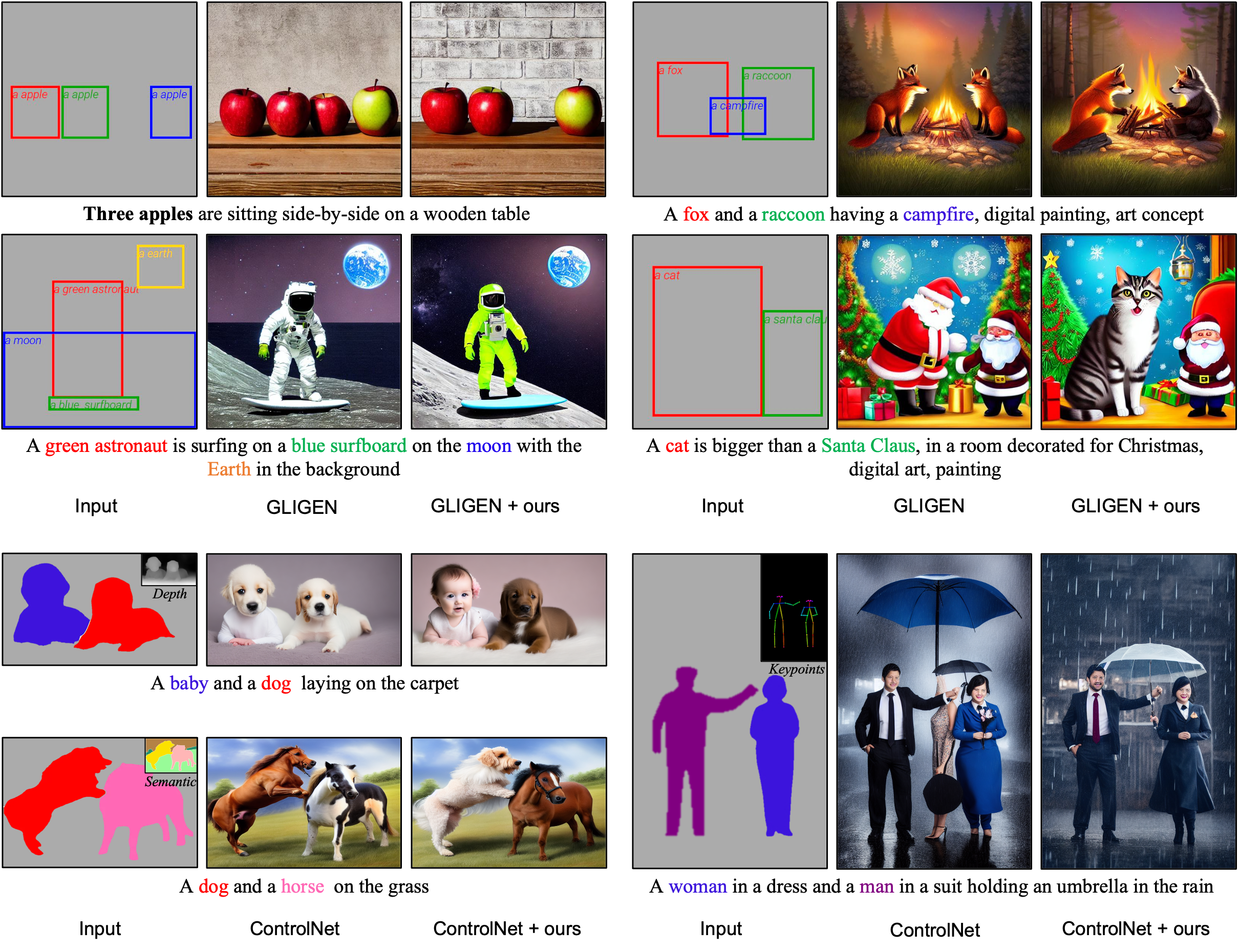
Controllable text-to-image synthesis with attention refocusing. We introduce a new framework to improve the controllability of text-to-image synthesis given the text prompts. We first leverage GPT-4 to generate layouts from the text prompts and then use grounded text-to-image methods to generate the images given the layouts and prompts. However, the detailed information, like the quantity, identity, and attributes, is often still incorrect or mixed in the existing models. We propose a training-free method, attention-refocusing, to improve on these aspects substantially. Our method is model-agnostic and can be applied to enhance the control capacity of methods like GLIGEN (top row) and ControlNet (bottom rows)